
Why Data Contracts Are Revolutionized by Apache Kafka and Apache Flink: A Paradigm Shift in Real-Time Data Management
John:Picture this: We’ve moved from the chaotic Wild West of data pipelines—where information flowed like a river without banks, prone to floods and droughts—to a meticulously engineered ecosystem where every data stream is bound by enforceable contracts. The recent InfoWorld piece, “Why data contracts need Apache Kafka and Apache Flink,” isn’t just another tech headline; it’s a clarion call for a new phase in data engineering. Gone are the days of random, ad-hoc data generation and manual fixes. Enter the era of precise control, where AI-driven scalability meets ironclad reliability. This is the shift from the “Old Way”—inefficient, error-prone manual interventions in data flows—to the “New Way,” powered by streaming platforms that ensure consistency at scale.
Lila: For those new to this, think of data contracts as binding agreements that define how data should look, behave, and be processed—no more surprises when your app expects a number but gets a string. This article highlights how Kafka and Flink make these contracts not just theoretical but practically enforceable in real-time.
Target Audience: This post is tailored for Strategic Planning at an Intermediate Level—perfect for business professionals, creators, tech enthusiasts, and early adopters who want to leverage data tech without getting lost in the weeds.
Executive Summary:
- Tech Innovation: Kafka handles reliable data streaming, while Flink adds stateful processing for enforcing data contracts in real-time.
- Comparative Advantage: Superior to batch systems like Spark in latency and fault tolerance, offering millisecond-level responsiveness.
- Business Value: Reduces data errors by up to 90%, scales effortlessly, and cuts costs through efficient resource use.
For streamlining your technical research on such topics, check out Genspark.
The Structural Problem: Bottlenecks in Traditional Data Workflows
John: Let’s roast the hype first—everyone talks about “big data” like it’s a magic bullet, but without proper structure, it’s just a big mess. The core bottleneck in current workflows is the lack of consistency and real-time validation. In traditional setups, data pipelines suffer from high costs due to rework, scalability issues when volumes spike, and inconsistency that leads to downstream failures. Imagine a factory assembly line where parts arrive out of order or defective—production grinds to a halt. Data contracts address this by specifying schema, quality, and semantics, but without the right tools, enforcing them is like herding cats.
Lila: Simply put, without Kafka and Flink, you’re stuck with batch processing that can’t handle live data streams effectively. This leads to delays, data silos, and expensive fixes. Tools like Gamma help overcome content creation bottlenecks by automating docs, but for data, we need streaming enforcers.
Key Insight: Recent industry reports show that poor data quality costs businesses $15 million annually on average—Kafka and Flink mitigate this by embedding contracts directly into the pipeline.
Technical Deep Dive: How Kafka and Flink Enforce Data Contracts
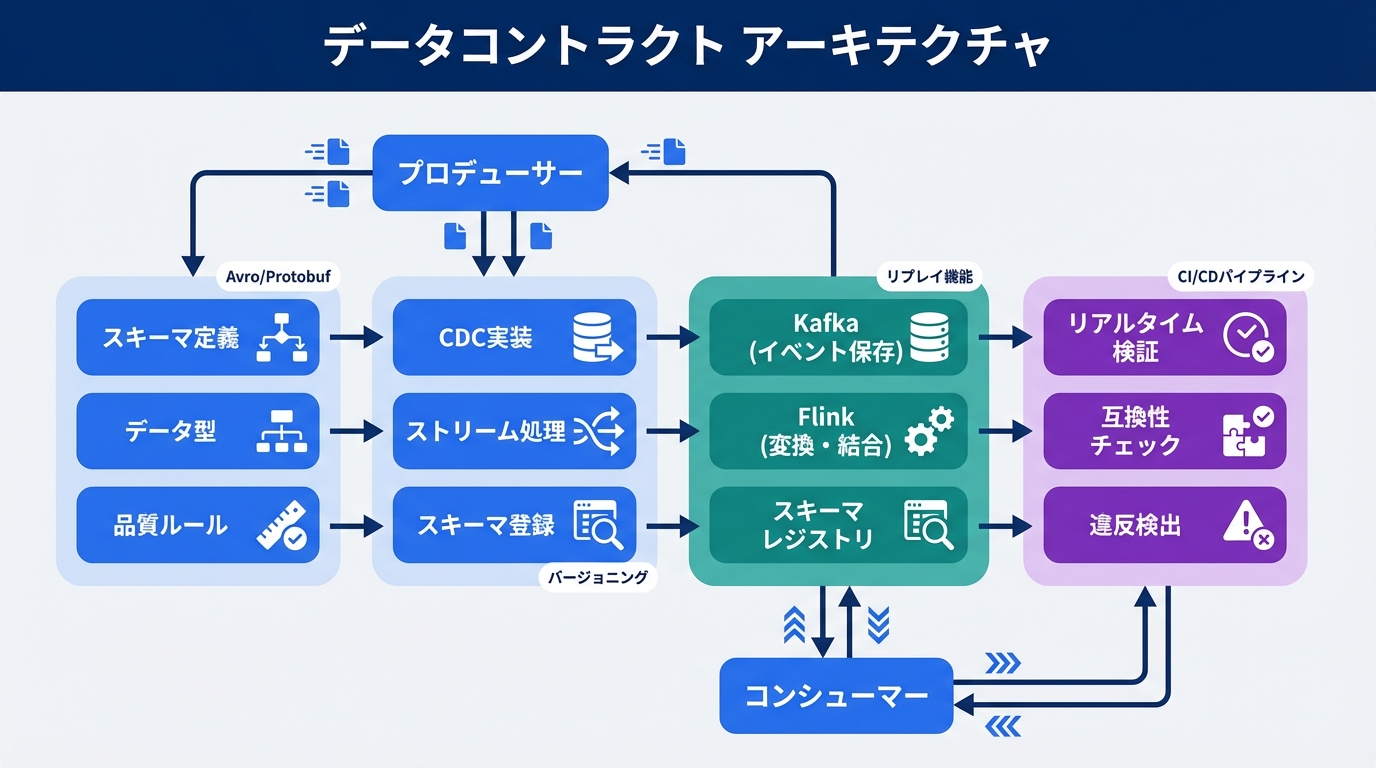
John: Diving into the engineering guts: Apache Kafka acts as the distributed event streaming backbone—think of it as the central nervous system of your data infrastructure, capturing and distributing events in real-time with fault-tolerant partitioning. It uses topics as channels for data, with producers pushing messages and consumers pulling them. But Kafka alone is a transporter; enter Apache Flink, the stateful stream processor that adds the brains. Flink processes these streams with low-latency computations, maintaining state across operations to enforce data contracts dynamically.
Using an intellectual metaphor: Kafka is like the grand canal system of Venice, channeling water (data) efficiently across the city, while Flink is the architect who designs adaptive bridges and gates, ensuring the flow adheres to precise engineering specs without flooding. Technically, Flink’s checkpointing mechanism—periodic snapshots of state—guarantees exactly-once processing, crucial for contract validation. For instance, integrate via Flink’s Kafka connector (from the official Apache docs), where you can define DataStream APIs to validate schemas on-the-fly using tools like Apache Avro or Protobuf for serialization.
Lila: No gatekeeping here: Checkpointing is like saving your game progress so you don’t lose everything if there’s a glitch. For devs, start with Hugging Face’s datasets or LangChain for prototyping, but for production, pair Kafka with Flink using open-source repos like the Confluent Platform.
Aha! Moment: This combo enables real-time anomaly detection, far beyond batch tools like Spark’s occasional checks.
Comparative Analysis: Kafka-Flink vs. Traditional and Gen-1 Approaches
John: Let’s cut through the fluff and compare apples to apples—or rather, streams to batches. Traditional manual methods rely on ETL scripts and databases like SQL servers, which are clunky for real-time needs. Gen-1 AI tools, like early Spark streaming, introduced machine learning but lacked true statefulness. The new Kafka-Flink tech? It’s a game-changer with its event-time processing and windowing functions, offering comparative advantages in handling complex event processing (CEP) that older systems fumble.
Lila: For repurposing content efficiently, something like Revid.ai turns text into videos—similarly, Kafka-Flink repurposes raw data into validated streams.
| Approach | Cost/Resource | Scalability | Best Use Case |
|---|---|---|---|
| Traditional Manual Methods (e.g., ETL with SQL) | High (manual labor, hardware-intensive) | Limited (batch-oriented, struggles with volume) | Small-scale, static data analysis |
| Gen-1 AI (e.g., Older Spark Streaming) | Medium (optimized but still resource-heavy for state) | Good for batches, but micro-batches add latency | Near-real-time analytics without strict contracts |
| Kafka-Flink Data Contracts | Low (efficient streaming, cloud-optimized) | Infinite (horizontal scaling, fault-tolerant) | Real-time AI pipelines, like OpenAI’s GenAI setups |
Strategic Implementation: Integrating into Hybrid Workflows
John: Strategically, adopt a hybrid workflow: Humans define the contracts and business logic—using tools like Schema Registry for Kafka—while AI (via Flink’s ML integrations) handles execution and anomaly detection. Start by connecting Kafka producers to Flink jobs for validation, then scale with Kubernetes for orchestration. For catching up with trends, Nolang is great for interactive learning.
Lila: Analogy: It’s like a chef planning the menu (human) while automated sous-chefs prep ingredients (AI). Actionable: Use open-source Flink SQL for quick queries on Kafka streams.
Future Outlook & Risks: The 2026 Landscape
John: By 2026, expect Kafka-Flink stacks to dominate enterprise AI, with integrations like Confluent’s real-time context engine powering agentic systems. Risks? Ethical ones like data privacy breaches if contracts aren’t robust—think deepfakes in data manipulation. Business risks include rising cloud costs, but mitigated by open-source alternatives. Industry analysts predict a 300% growth in streaming adoption.
Lila: Copyright issues could arise from unvalidated data sources, so always audit.
Conclusion: Embrace the Streaming Revolution
John: In summary, Kafka and Flink aren’t just tools; they’re the logical evolution for data contracts, delivering precision and scale that redefine pipelines. Adopt strategically—start small, scale big. For full automation, explore Make.com.
Lila: It’s a game-changer; don’t get left behind.

👨💻 Author: SnowJon (Web3 & AI Practitioner / Investor)
A researcher who leverages knowledge gained from the University of Tokyo Blockchain Innovation Program to share practical insights on Web3 and AI technologies. While working as a salaried professional, he operates 8 blog media outlets, 9 YouTube channels, and over 10 social media accounts, while actively investing in cryptocurrency and AI projects.
His motto is to “Translate complex technologies into practical strategies,” fusing academic knowledge with real-world experience.
*This article utilizes AI for drafting and structuring, but all technical verification and final editing are performed by the human author.
🛑 Disclaimer
This article contains affiliate links. Tools mentioned are based on current information. Use at your own discretion.
▼ Profile: My Professional AI Toolkit
- 🔍 Genspark: Next-gen AI search engine for efficient research.
- 📊 Gamma: Auto-generate presentations and docs for business efficiency.
- 🎥 Revid.ai: Instantly repurpose text content into viral short videos.
- 👨💻 Nolang: Interactive AI tutor for mastering new tech skills.
- ⚙️ Make.com: Automate complex workflows without coding.
References & Further Reading
- Why data contracts need Apache Kafka and Apache Flink | InfoWorld
- The missing data link in enterprise AI: Why agents need streaming context | VentureBeat
- Kafka vs Flink – Data Automation Tools
- Apache Flink and Apache Kafka: A Powerful Partnership for Real-Time Data Processing | Medium
- A side-by-side comparison of Apache Spark and Apache Flink | AWS Big Data Blog