Tired of Juggling Your Data? Here’s a Smarter Way to Move It Around!
Hello everyone, John here! If you’ve ever tried to move house, you know how complicated it can be. You’re packing boxes from the kitchen, the bedroom, the garage… and each one needs to be handled differently. Now, imagine doing that with data. Companies today have data coming from all over the place: traditional databases, online apps like Salesforce, and simple file systems. Getting all that data to one central place can be a real headache.
The old way of doing this involved building a custom “moving plan” for every single data source. Add a new source? You have to write a whole new plan from scratch. It’s slow, rigid, and a nightmare to maintain. Today, we’re going to look at a much more elegant solution discussed in a recent article: a “metadata-driven” framework. It’s like creating a master-moving-plan that can adapt to any situation without a complete rewrite!
The Problem: Why Old-Fashioned Data Moving is So Hard
Imagine you run a delivery service. The traditional way of moving data is like having to build a brand-new, unique truck for every single package you deliver. Delivering a box from City A to City B? Build a truck. Delivering an envelope from City C to City D? Build another, totally different truck. You can see how this would quickly become incredibly expensive and inefficient.
This is what life was like for data architects. Every new data source required a custom-built data pipeline.
Lila: “Hold on, John. What exactly is a ‘data pipeline’? And what does ETL mean? I saw that in the article.”
John: “Great questions, Lila! Think of a pipeline as an assembly line for data. It’s a series of steps that automatically moves data from a starting point to a destination. And ETL is just a fancy acronym for the three main steps in that process:
- Extract: Grabbing or ‘extracting’ the data from its original home.
- Transform: Cleaning, sorting, or changing the data so it’s in the right format for its new home.
- Load: Putting or ‘loading’ the clean data into the final destination, like a central data warehouse.
So, the old method meant building a whole new ETL pipeline for every single data source. The author of the article realized there had to be a better way.”
The Solution: The “Cookbook” Approach for Data
Instead of building a new truck every time, what if you had one, super-smart, adaptable truck? And instead of hard-wiring the directions into the truck’s GPS, you just handed the driver a new piece of paper with instructions for each trip. This is the core idea behind a metadata-driven system.
Lila: “Okay, but what is ‘metadata’?”
John: “Excellent question. ‘Metadata’ is just a simple way of saying ‘data about data.’ For example, if your data is a photograph, the metadata would be information like the date the photo was taken, the GPS location, and the type of camera used. In our data-moving world, the metadata is the set of instructions: where to get the data, what kind of data it is, and where it needs to go.
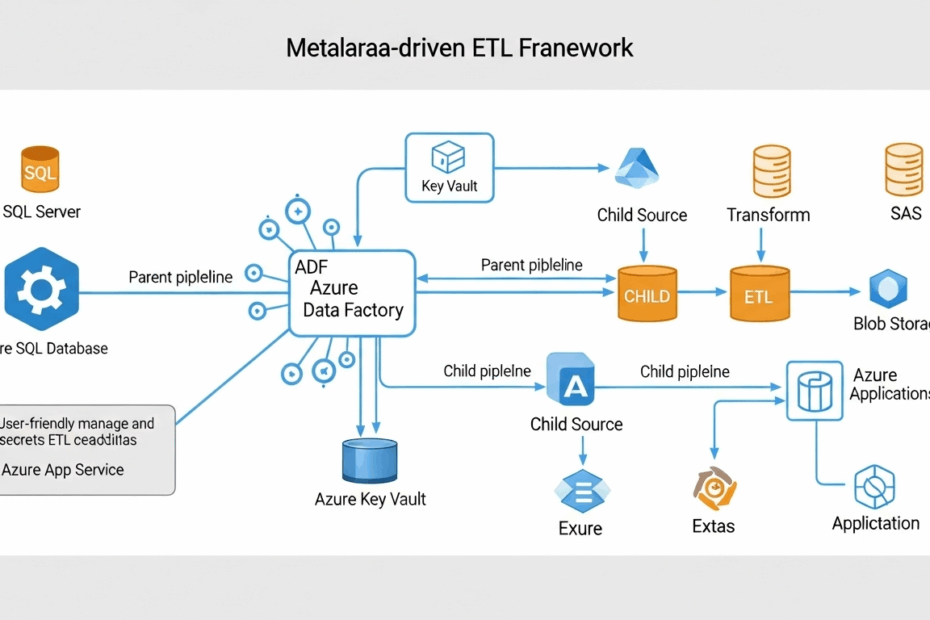
This approach is like having a master cookbook for all your data recipes. Instead of the instructions being part of the pipeline itself, they are stored separately in a central “cookbook” (in this case, an Azure SQL Database). The main data-moving process simply reads the recipe it needs from the cookbook and follows the instructions. Need to add a new data source? Just add a new recipe to the book! No need to rebuild the whole kitchen.
How the Smart System is Built: Meet the Team
The author built this clever system using a few key components from Microsoft Azure (which is Microsoft’s cloud computing platform). Let’s think of it as a well-organized kitchen crew.
The Master Cookbook (The Metadata)
This is the heart of the system, a database that holds all the instructions. It’s organized into a few key sections:
- Connections List: This is the “address book.” It stores the location of all the data sources (where to pick up data) and destinations (where to drop it off).
- The Daily To-Do List (ETLConfig): This is where the specific recipes are. For each job, it says exactly which data to move, what order to do things in, and any special steps to take along the way.
* Operations Menu: This lists the different types of jobs we can do. For example, “Move data from one database to another” or “Move a file from a server to cloud storage.”
The Head Chef (The Parent Pipeline)
In the world of Azure, the tool for building these data assembly lines is called Azure Data Factory (ADF). The architect designed a “Parent Pipeline” in ADF to act as the head chef or project manager. This parent pipeline is very smart, but it doesn’t do any of the actual moving itself. Its only job is to read the instructions from the “cookbook” (the metadata) and then delegate the tasks to the right specialists.
The Specialist Chefs (The Child Pipelines)
The parent pipeline hands off the actual work to a team of “Child Pipelines.” Each child pipeline is a specialist, designed to do one type of job very well. There might be one specialist for database-to-database moves, another for handling files, and so on. These child pipelines are like templates. The parent pipeline can use the same “database specialist” for hundreds of different database-moving jobs, just by giving it different instructions (metadata) each time. This makes the system incredibly efficient and easy to expand.
Keeping Everything Safe, Reliable, and Easy to Use
A great system isn’t just about moving data; it’s about doing it securely and reliably.
Security First: You wouldn’t write your bank password on a sticky note for everyone to see. Similarly, this system uses something called Azure Key Vault—a super-secure digital safe—to store sensitive information like passwords and connection details. The “cookbook” only stores a reference to the secret, not the secret itself, so everything stays locked up tight.
Running the Show: The system is flexible. You can set up jobs to run on a schedule (e.g., every night at midnight), trigger them with the push of a button for on-demand tasks, or even have them start automatically when a new file appears in a folder.
Watching and Alerting: What happens if a job fails? The system has a robust logging and monitoring setup. It keeps a diary of every job—when it started, when it finished, and whether it was successful. If something goes wrong, it can automatically send alerts to the IT team so they can fix it.
An Interface for Everyone: To top it all off, the architect built a simple web-based user interface (UI). This means that even non-technical staff can add a new data source or change a schedule by filling out a simple form, without ever having to look at a single line of code. This empowers more people and frees up the tech team for more complex work.
Overcoming a Few Bumps in the Road
No project is without its challenges. The author ran into a few limitations with the tools. For example, one part of Azure Data Factory had a limit on how many different “choices” it could handle at once. The clever workaround was to create categories—grouping similar jobs together first, which allowed the system to handle a much larger number of tasks. This kind of problem-solving is what separates a good design from a great one.
My Final Thoughts
John’s Take: I’m really impressed by this design. It’s a perfect example of how thinking ahead can save you countless hours down the road. Building this kind of metadata-driven framework requires more planning upfront, but the payoff in flexibility, scalability, and ease of maintenance is huge. It’s about building a system that’s meant to last and grow, not just one that solves today’s problem.
Lila’s Take: As a beginner, the “cookbook” and “kitchen crew” analogies really made this click for me! It seems so logical to keep your instructions separate from your workers. It makes the whole process feel less intimidating and much more organized. The idea of having a simple website to manage it all is the cherry on top!
This article is based on the following original source, summarized from the author’s perspective:
Designing a metadata-driven ETL framework with Azure ADF: An
architectural perspective