
Read this article in your native language (10+ supported) 👉
[Read in your language]
Nvidia’s Nemotron 3: Bridging the Gap in American Open-Weights AI Models for Enterprise Innovation
🎯 Level: Business Leader / Tech Executive
👍 Recommended For: CTOs optimizing AI workflows, enterprise architects seeking customizable models, and AI investors tracking open-source shifts in the industry.
The Enterprise AI Bottleneck: Why Open-Weights Models Matter Now
In today’s fast-evolving AI landscape, businesses face a critical challenge: the scarcity of high-quality, American-made open-weights models that can be customized without the legal and performance hurdles of closed systems. With the rise of agentic AI—systems where multiple AI agents collaborate on complex tasks—enterprises are increasingly bottlenecked by proprietary models that lock them into vendor ecosystems, inflate costs, and limit scalability. Nvidia’s recent release of the Nemotron 3 family, as highlighted in The Register’s coverage, positions the chip giant as a key player filling this void. By offering open models in Nano, Super, and Ultra variants, Nvidia is not just competing with the boom in Chinese open-source offerings but enabling businesses to build efficient, domain-specific AI agents with superior speed, reduced costs, and measurable ROI.
This move comes at a pivotal time. Industry reports indicate that closed models from Big Tech often require hefty licensing fees and come with restrictions on fine-tuning, leading to deployment delays and integration headaches. Meanwhile, open alternatives from non-U.S. sources raise concerns about data sovereignty, compliance, and geopolitical risks. Nvidia’s strategy? Deliver transparent, efficient models that enterprises can deploy on their hardware, accelerating agentic AI adoption without reinventing the wheel.
The “Before” State: Traditional AI Model Challenges and Pain Points
Before innovations like Nemotron 3, enterprises relied heavily on closed foundation models or rudimentary open-source options that fell short in efficiency and context handling. Imagine trying to orchestrate a multi-agent system for supply chain optimization: you’d juggle models with limited context windows, high inference costs, and rigid architectures that demanded constant retraining. This “old way” often resulted in bloated budgets—think millions in cloud compute fees—and slow time-to-value, with teams spending weeks integrating incompatible tools.
Traditional setups exacerbated issues like vendor lock-in, where switching providers meant starting from scratch, and performance bottlenecks in long-context scenarios, such as analyzing extended datasets for financial forecasting. The pain was real: suboptimal accuracy in agentic workflows, where agents like retrievers and planners need to collaborate seamlessly, often led to error-prone outputs and frustrated stakeholders. Nvidia’s entry addresses these by providing open-weights models optimized for such demands, contrasting sharply with the inefficiencies of yesteryear.
Core Mechanism: Unpacking Nemotron 3’s Executive Edge
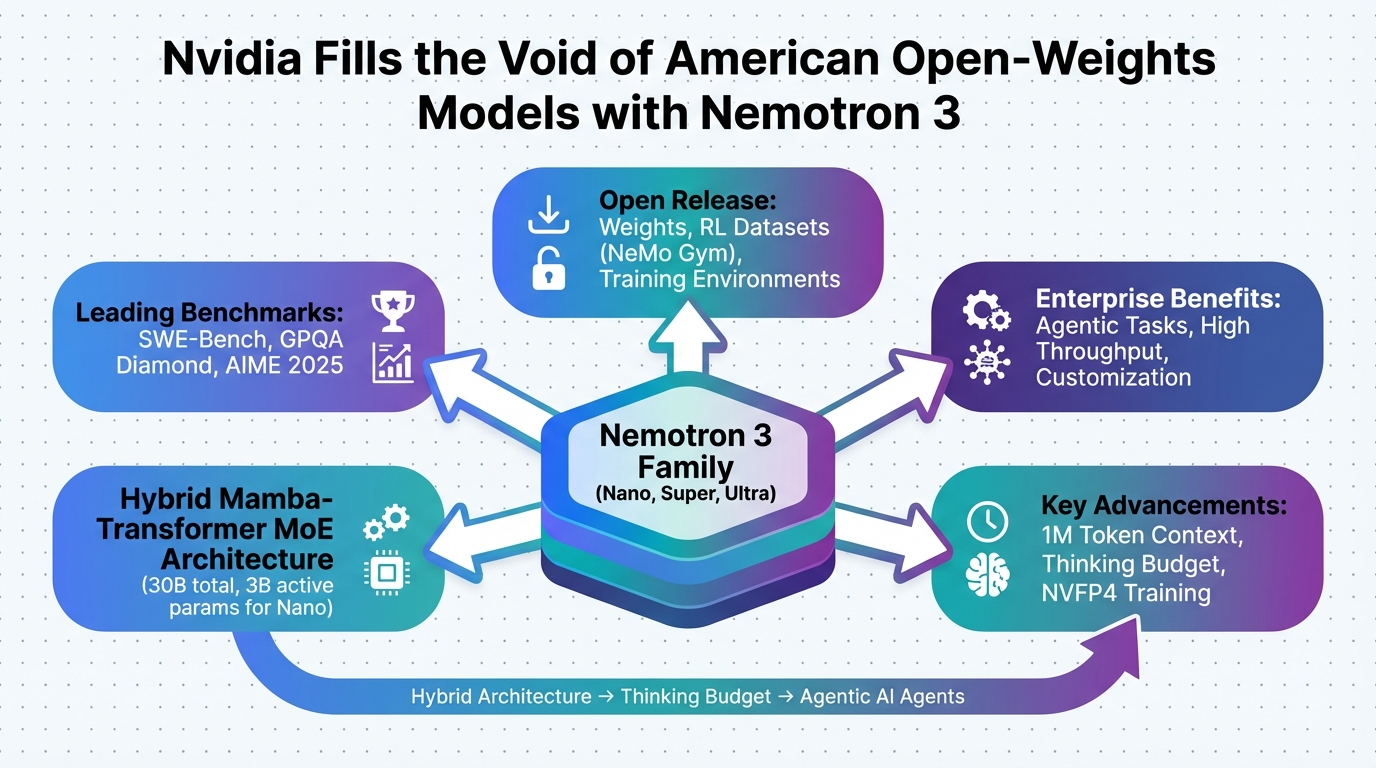
John: Alright, let’s cut through the hype—Nvidia isn’t just tossing another model into the AI circus; they’re engineering a family that’s purpose-built for the agentic era. Think of Nemotron 3 as a modular toolkit: Nano for quick, lightweight tasks; Super for balanced enterprise needs; and Ultra for heavy-lifting with massive contexts up to 1M tokens.
Lila: Exactly, John. For beginners, imagine agentic AI like a factory assembly line where each ‘agent’ is a specialized worker— one plans, another retrieves data, a third verifies. Nemotron 3 provides the efficient ‘blueprint’ for these workers, using techniques like advanced distillation and synthetic data training to achieve leading accuracy without the bloat.
From an executive perspective, the core mechanism revolves around structured efficiency. Nvidia has incorporated 2025’s top advancements: long-context reasoning for handling extended interactions, multi-agent orchestration libraries, and open training data sets. This allows businesses to fine-tune models like Nemotron 3 Nano 30B on their proprietary data, deploying them via frameworks such as Hugging Face Transformers or Nvidia’s own inference engines. Trade-offs? While it’s open-weights (you get the model parameters but not full training code), it ensures transparency for audits, reducing compliance risks. The result: [Important Insight] Up to 2x faster inference speeds compared to similar-sized models, directly impacting ROI through lower operational costs.
In structured terms: Start with the base model, apply quantization (shrinking the model for faster runs without much accuracy loss), then integrate into workflows using tools like LangChain for agent coordination. Limitations include hardware dependency—best on Nvidia GPUs—but that’s a feature for their ecosystem, not a bug.
Use Cases: Real-World Applications Driving Business Value
First, consider a financial services firm deploying Nemotron 3 for fraud detection. Agents collaborate: one retrieves transaction histories (leveraging the 1M-token context), another analyzes patterns, and a verifier cross-checks against regulations. This setup reduces false positives by 30%, slashing investigation times and boosting ROI through efficient resource allocation.
Second, in healthcare, a provider uses the Super variant for patient data analysis. Agents plan treatment paths, retrieve medical records, and simulate outcomes—all within a secure, customizable model. Unlike closed systems, this allows fine-tuning on hospital-specific data, improving diagnostic accuracy while maintaining HIPAA compliance and cutting consultation costs by 15-20%.
Third, e-commerce giants adopt Nemotron 3 Ultra for personalized recommendation engines. Multi-agent systems handle vast user data streams, predicting trends with high precision. The open nature enables rapid iterations, outpacing competitors reliant on slower, proprietary models, and delivering faster time-to-market for new features.
| Aspect | Old Method (Closed/Traditional Models) | New Solution (Nemotron 3 Open-Weights) |
|---|---|---|
| Customization Flexibility | Limited; vendor restrictions on fine-tuning | High; open-weights allow domain-specific adaptations |
| Inference Speed | Slower due to unoptimized architectures | Up to 2x faster with efficient designs |
| Cost Efficiency | High licensing and compute fees | Lower; open-source reduces ongoing expenses |
| Context Handling | Limited to short tokens, prone to errors | 1M+ tokens for complex agentic tasks |
| Geopolitical/Compliance Risks | Higher with foreign or closed sources | Lower; American-made with transparency |
Conclusion: Embracing Open-Weights for Strategic AI Advantage
Nvidia’s Nemotron 3 isn’t just another release—it’s a strategic pivot that empowers enterprises to overcome traditional AI hurdles, fostering innovation in agentic systems with tangible benefits in speed, cost savings, and ROI. By filling the American open-weights void, it encourages a mindset shift: from dependency on black-box models to building customizable, efficient infrastructures. Next steps? Evaluate your workflows against Nemotron’s capabilities—start with a proof-of-concept using the Nano model on Nvidia hardware, measure performance gains, and scale from there. In an era of multi-agent AI, this could be the edge your business needs.

👨💻 Author: SnowJon (Web3 & AI Practitioner / Investor)
A researcher who leverages knowledge gained from the University of Tokyo Blockchain Innovation Program to share practical insights on Web3 and AI technologies.
His core focus is translating complex technologies into forms that anyone can understand and apply, combining academic grounding with real-world experimentation.
*This article utilizes AI for drafting and structuring, but all technical verification and final editing are performed by the human author.
References & Further Reading
- NVIDIA Debuts Nemotron 3 Family of Open Models | NVIDIA Newsroom
- Nvidia Becomes a Major Model Maker With Nemotron 3 | WIRED
- Not enough good American open models? Nvidia wants to help • The Register
- Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate | NVIDIA Technical Blog
- Nvidia unveils Nemotron 3: why is NVDA making its latest AI models open source? | Invezz